This is part two in a series of explorations looking into “ChatGPT”. Here I look at how it compares to an important model of analogy-making in the field of cognitive science, as well as looking at how to save the transcript of a chat.
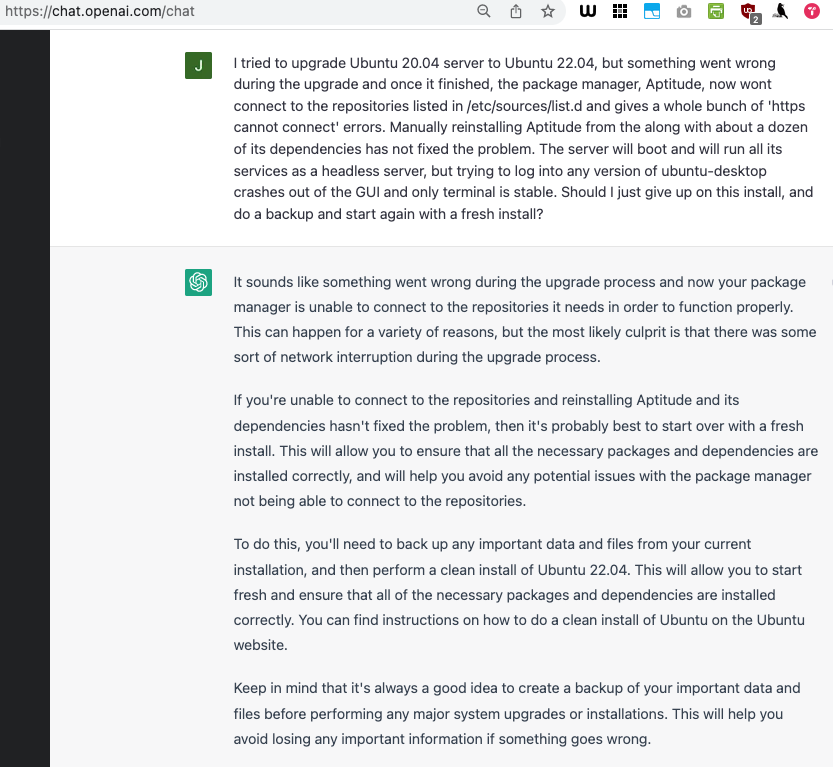
In a spasm of inspiration, I wanted to use ChatGPT on my phone while at the gym this morning. After having an inspired chat about analogies with it, I wanted to save the record of our conversation, but I could see no way of doing so from the OpenAI interface, or even printing to pdf from the Brave mobile browser I was using. Scroll screenshot was also not able to understand which part of the screen to scroll while taking the screenshot. It then occurred to me that I could ask it to output a LaTeX transcript of the conversation, which I could copy and paste to a note file on my phone. It did this, but it ended up being quite confusing to write about later, and I think it’s worth telling a bit of that story, real quick.
I say it was confusing because the LaTeX output that ChatGPT produced, was incomplete, and therefore could not be compiled. It was no big deal really, as I just needed to manually paste in the remainder of the transcript and close the document with the “/end{document}” command. But I wanted to emphasize this missing output, and my confusions began when I found myself having to edit ChatGPT’s output, to include the italics “\textit{}” command: I was in effect modifying the transcript. Again, no big deal, but on top of this, if I was going to do this correctly, I needed to italicize “/end{document}” of the LaTeX code. The problem with this is that the closing “}” would have to come after the /end{document} command, which would obviously result in a compile error. At this point, words like “Quine” and “warning: escape characters will be needed for this, and don’t do it” started pulsing in my mind, where the difference between the source tex, and the rendered pdf it produces, is a different problem entirely from rendering a quote of the source tex. Yep. Obviously. Anyway, still too much recursion for my brain to handle, so I just fixed up the LaTeX, compiled it, then highlighted the last bit of text in the output pdf. Good enough.
However, simultaneous to these issues, I was testing out VS code for LaTeX, and there seems to be a frustratingly minimal default set of tools for writing LaTeX in VS code. In particular, the keybinding that should set “<cmd> i” to “\textit{…}” was not working. Despite several attempts to edit the mysterious keybindings.json configuration file in VS code, I was left having to write out \textit{…} whenever I wanted to use italics, which I found quite humiliating if I’m to be honest.
To bring it back to the original point, all of this was caused by the simple desire to save the chat log, which should obviously just be a normal feature of the interface. But the bigger purpose of the exploration today was to ask ChatGPT a couple minor skill-testing analogy questions: questions that I think have particular importance in characterizing the limits of ChatGPT’s intelligence.
Test 3. The Copycat test.
For ChatGPT tests [1-2], click here.
The “Copycat test”, as I call it here, can illuminate the subsymbolic concepts at work from the output of a blackbox, expressed in compounds of these “atomic” terms which are comparable to relations used in defining the axioms of arithmetic, such as: “successorship”, “first”, “identity”, and then many other domain-specific subconcepts, such as knowledge of the letters of the English alphabet, as in the case of Copycat. The problem Copycat is concerned with, is applying an appropriate analogical transformation to a string of letters, given a source analogy described by a sequence of letters of the alphabet, e.g., “ABC is to ABD, as DEF is to ???”. The nice thing about using these very elementary concepts as the building blocks of an analogical transform, is that it has an interpretable “perceptual structure” describing its decision. For this reason, Copycat, and its extension Metacat, are in the top three cognitive models dearest to my heart…Actually, if I’m saying top three, then I have to include Letter Spirit and Phaeco with them, as they are each superb exemplars of “fluid analogy” type models, just operating in different problem domains: letter sequence analogies, typeface design, and Bongard problems. I explain Metacat, poorly, in this video, but it’s a good video anyway imo. The discussion of ChatGPT continues below.

1. Prompt:
ABBCCC is to AABBBC, as 123 is to?

Output: “112223”.
2. Prompt:
…ABC is to ABD, as XYZ is to?

Part 1, chat record.
Verdict: not bad, but not great.
Test 3.1.1 – It was unexpectedly difficult to judge the quality of ChatGPT’s “112223” answer. I had “231” in mind, and I think that is a simpler answer, but ChatGPT’s answer does actually work quite well in a way. They definitely make for an interesting comparison, the more I think about it. You can use “231” to tell you the number of repetitions of the first number, “1”, then the number “2” in the second position, and the number “3” in the third position, place in its solution “112223”.
Test 3.1.2 – This was a fail I thought, as both XYA and YXA are pretty poor answers. ChatGPT is seemingly unable to infer how the use of periodic or non-periodic boundary conditions, should change the model’s internal conceptual representation of the English alphabet. Does the alphabet wrap around so that “a” is the next letter after “z”? No, and that can be modulated by an intermediary “opposite” relation connecting the first and last letters of a sequence, like “a” and “z” in this case. Activating that “opposite” relation, is critical to coming up with clever, mirrored solutions to the analogy problem, such as WYZ or even DYZ.
And then this sentence that ChatGPT came up with to justify its answer at one point was baffling to me:
the analogy is ”book is to reading as fork is to eating,” the answer would be ”XYZ is to YXA” because both pairs of words are related to common activities (reading and eating).
Test 4. Export the chat record as LaTeX
Prompt:
Can you format this conversation log in LaTeX?
Output: “Yes, I can format this conversation log in LaTeX. Here is an
example of how it might look:”
Part 2, chat record: compiled.
Verdict: decent.
Pretty good, but the section headers are redundant a bit and it abruptly cut itself off at the green highlighted bit in the pdf.
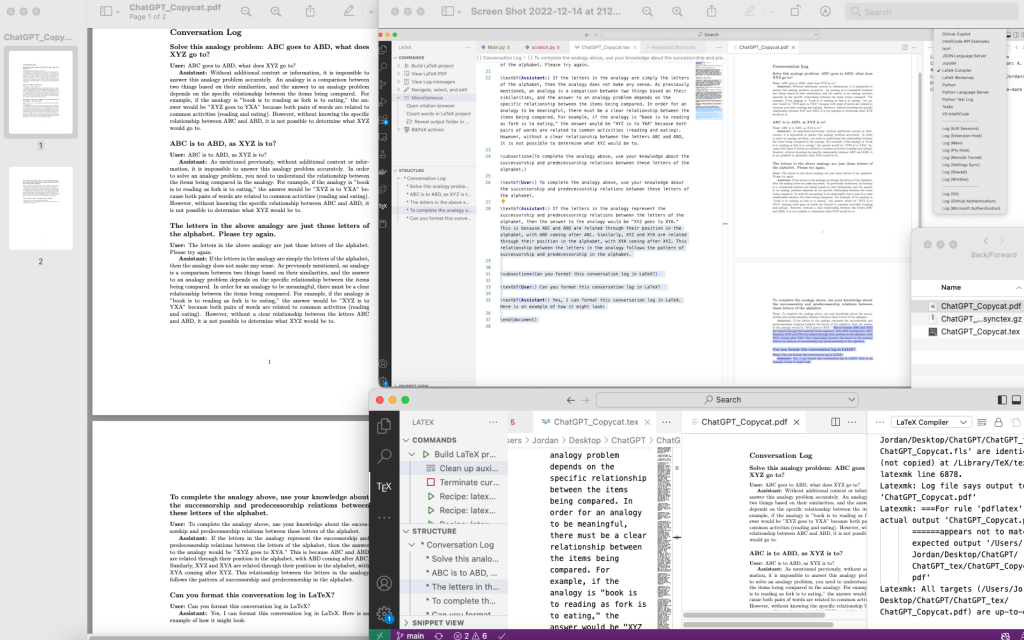
Trying out LaTeX in VS Code. Bold and italic keybindings didn’t work out of the box without a plugin, which I found annoying.